
Reading notes: mHC: Manifold-Constrained Hyper-Connections (DeepSeek) 🐋
2026.01.02


Modern AI models keep getting larger and more powerful, but training them reliably is still surprisingly fragile. This post explains a recent DeepSeek paper that shows how a small architectural fix can make large models more stable as they scale.
Audio summary by NotebookLM
1. The quiet problem holding big models back
Modern AI models keep getting deeper and more powerful, but training them is still surprisingly fragile. Small design choices deep inside a model can decide whether training is smooth or suddenly breaks.
One of the biggest hidden problems is how information flows through very deep networks. If signals weaken, explode, or get distorted as they move through layers, learning becomes unstable and expensive.
In their paper mHC: Manifold-Constrained Hyper-Connections, researchers from DeepSeek focus on fixing exactly this problem. Instead of proposing a new model or more data, they improve one of the most basic building blocks of neural networks: the residual connection. That small change turns out to matter a lot at scale.
2. What a residual connection really does

Before residual connections, deep neural networks were hard to train. As information passed through many layers, important signals slowly faded away.
The figure above shows the simple idea that fixed this. Instead of forcing information to pass only through a complex transformation, the model keeps a shortcut. The input x skips around the layer and is added back to the output F(x).
In diagram A, this idea appears in its simplest form. The layer tries to learn something useful, but if it fails, the original signal still passes through unchanged. Nothing is lost.
Diagram B shows how this works in real networks. The main path applies multiple weight layers and nonlinearities, while the shortcut stays clean and untouched. At the end, both paths are added together.
This single idea—adding F(x) + x instead of replacing x—is what made very deep models trainable in practice. Everything in this paper builds on that foundation.
3. Where Hyper-Connections went wrong
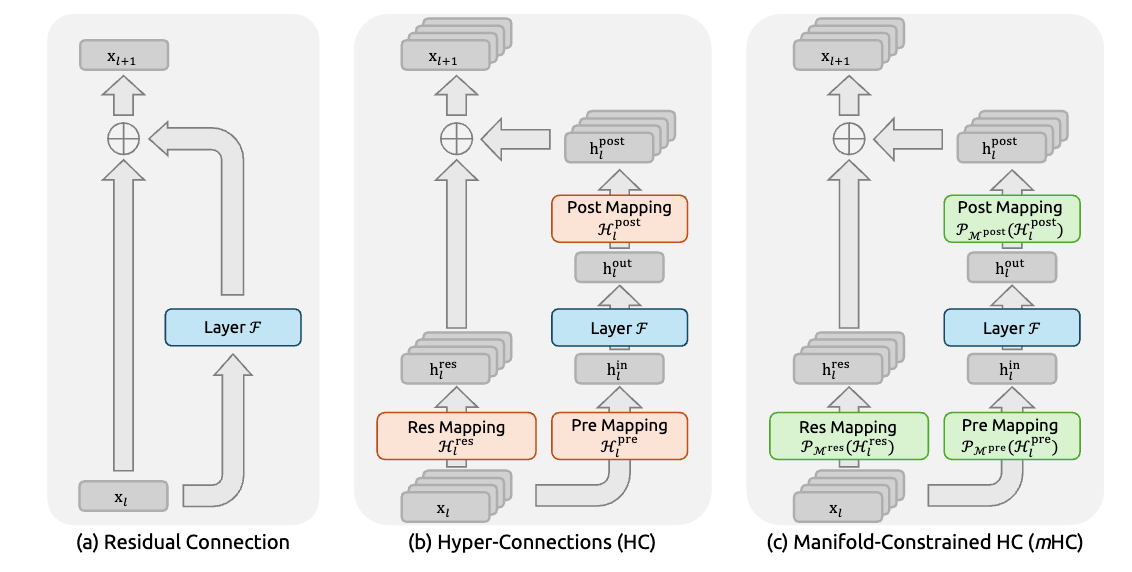
As models grew larger, researchers tried to make residual connections more powerful. One idea was Hyper-Connections, which replace a single shortcut with multiple parallel ones.
You can think of this as turning a one-lane road into a multi-lane highway. Information can flow through several paths, and the model learns how to mix them before and after each layer. This increases flexibility and often improves performance.
But there’s a catch. These paths are unconstrained. Nothing prevents them from amplifying signals too much or shrinking them too far. As models get deeper, these effects stack up.
In practice, this shows up as unstable training: sudden loss spikes, exploding gradients, and runs that fail for no obvious reason. Hyper-Connections add power, but they quietly remove an important safety mechanism.
4. The key idea behind mHC
mHC keeps the multi-path idea but adds one simple rule: layers are only allowed to rebalance information across paths, not make it stronger or weaker overall.
In plain terms, a layer can mix signals, but it must conserve the total amount of signal. Nothing is allowed to blow up or disappear.
This rule is enforced with a mathematical constraint, but the intuition is simple. Every shortcut behaves like a safe mixer instead of an uncontrolled amplifier. Even when many layers are stacked together, information stays stable.
The result is the best of both worlds: richer information flow from multiple paths, without the training chaos that usually comes with it.
5. The real takeaway for the future of AI models
What makes this paper stand out is not just the idea, but the execution. DeepSeek didn’t stop at theory. They rebuilt kernels, optimized memory usage, and reworked pipeline parallelism to make mHC work at 27B parameter scale with only about 6.7% training overhead.
The bigger lesson is important. The next wave of AI progress may come less from “bigger everything” and more from better structure and smarter constraints. mHC is a strong signal that architectural discipline, not brute force, is becoming the real edge in large-scale AI research.