
Reinforcement Learning from Human Feedback (RLHF), explained simply


Large language models gather most of their knowledge from huge quantities of text. This pretraining helps them understand what is probable, but it doesn't necessarily teach them what is good, helpful, or appropriate. That's where RLHF comes in - it adds human judgment to guide the training, enabling modern models to better follow instructions, reason carefully, and steer clear of obviously undesirable behavior.
At a high level, RLHF answers a simple question:
How do we steer a pretrained model toward outputs humans actually prefer?
Why is RLHF needed?
Pretraining focuses on predicting the next token, but it doesn't necessarily teach the model what is most useful or aligned with human preferences. That’s why models might sometimes be verbose, evasive, or even confidently wrong. Supervised fine-tuning can help a bit by teaching the model to mimic examples, but it doesn’t really teach it about tradeoffs or what humans prefer. That’s where RLHF comes in — it helps the model learn by comparing different outputs and understanding which ones humans like best.
RLHF also helps us improve continuously. Rather than setting strict rules, we listen to feedback to understand what it truly means. Over time, this approach of learning from feedback has become at the heart of how instruction-following and reasoning models develop and get better.
What does RLHF actually do?
Most RLHF pipelines follow the same structure:
Generate multiple responses to a prompt.
Score or compare them using human feedback (or a model trained on human feedback).
Update the model to increase the probability of preferred responses while limiting harmful drift.
Different techniques approach this update in unique ways, each relying on different methods and tools. This variety makes the process interesting and shows how versatile the field is.
Early RL-based approaches
REINFORCE
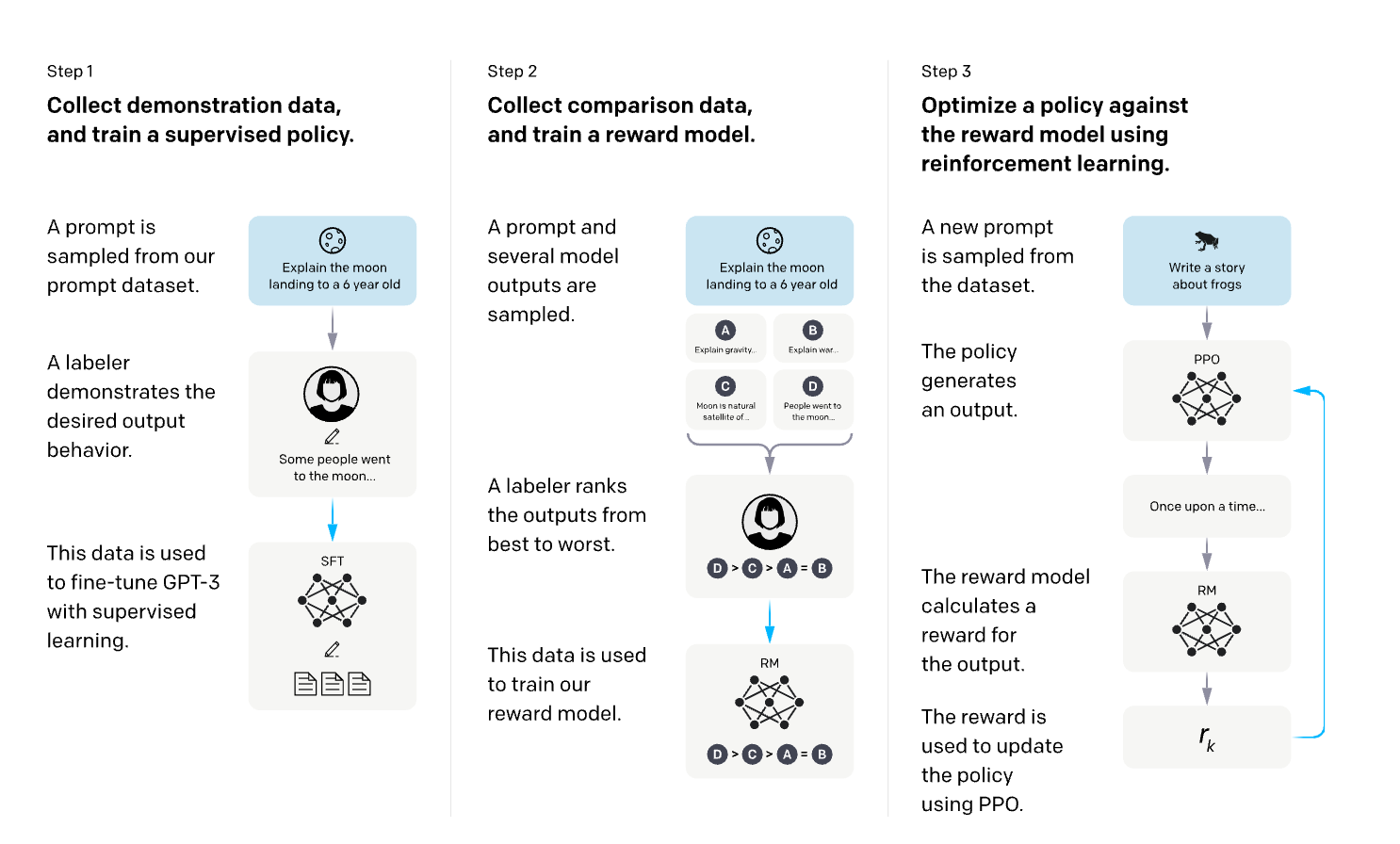
The simplest RL approach is to generate an output, get a reward, and then boost the chances of producing high-reward outputs again. While it's conceptually simple, it can sometimes be quite unstable due to its high variability. Thankfully, most of the newer methods have been developed to tackle these challenges and make the process more stable.
OpenAI. (2022). Training language models to follow instructions with human feedback (InstructGPT paper). https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf
TRPO (Trust Region Policy Optimization)
TRPO helps keep learning steady by making sure each update stays close to the last policy. This approach avoids drastic changes, though it involves some complex constrained optimization. While it has shown that stability is achievable, it can be a bit too heavy for large projects.
Schulman, J., Levine, S., Abbeel, P., Jordan, M., & Moritz, P. (2015). Trust Region Policy Optimization. arXiv. https://arxiv.org/abs/1502.05477
 in AI | by Oleg Latypov | Medium")
PPO (Proximal Policy Optimization)
PPO makes TRPO easier by using clipped objectives or gentle KL penalties instead of strict constraints. In RLHF, PPO usually involves a reward model, a value (critic) model, and a reference model. It has become the go-to method, but it can be quite demanding on computational resources and requires careful tuning.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv. https://arxiv.org/abs/1707.06347
Critic-free reinforcement learning
SCST (Self-Critical Sequence Training)
SCST builds on the model’s own greedy output as a helpful baseline, making it easier to reduce variance. This approach removes the need for a learned critic, which can simplify things, although it may still face some challenges with stability when scaled up. It also played a role in shaping later RLHF methods.
Rennie, S. J., Marcheret, E., Mroueh, Y., Ross, J., & Goel, V. (2016). Self-critical sequence training for image captioning. arXiv. https://arxiv.org/abs/1612.00563

RLOO (REINFORCE Leave-One-Out)
RLOO samples various responses for each prompt and calculates how each one compares to the others. This approach eliminates the need for a critic, all while maintaining low variance. It's a simpler and more cost-effective method compared to PPO.
Ahmadian, A., Cremer, C., Gallé, M., Fadaee, M., Kreutzer, J., Pietquin, O., Üstün, A., & Hooker, S. (2024). Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs. arXiv. https://arxiv.org/abs/2402.14740

GRPO (Group Relative Policy Optimization)
GRPO simplifies the process of comparison by focusing on advantages within a sample group of responses. Rather than predicting specific values, the model learns through comparing different options. This approach not only conserves memory but also proves to be very effective for thinking-intensive tasks.
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv. https://arxiv.org/pdf/2402.03300v3.pdf
Ranking and comparison-based RL
Rank-based policy optimization
Some methods prefer using rankings or percentiles instead of numeric rewards. People often find it easier to rank things rather than assign scores, and ranking helps avoid problems with reward scales. These approaches are quite similar to GRPO in their core idea.
Zhu, Y., Steck, H., Liang, D., He, Y., Ostuni, V., Li, J., & Kallus, N. (2025). Rank-GRPO: Training LLM-based conversational recommender systems with reinforcement learning. arXiv. https://arxiv.org/abs/2510.20150
Removing RL loops: direct preference optimization
DPO (Direct Preference Optimization)
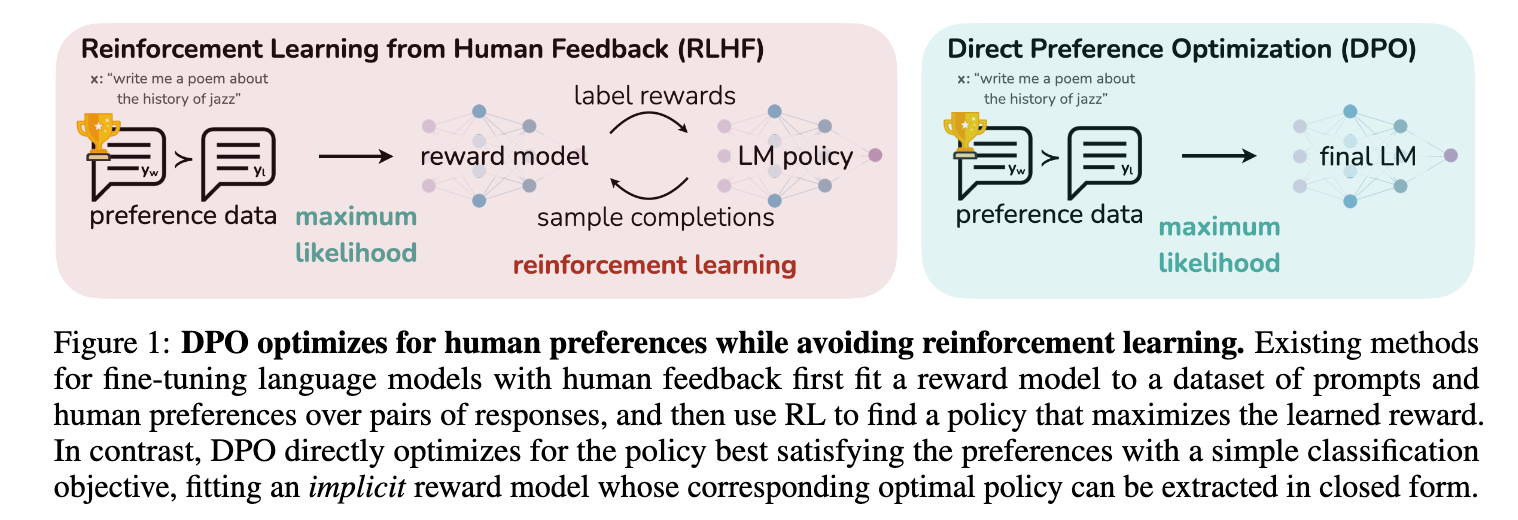
DPO reimagines the RLHF goal as a supervised learning task focusing on preference pairs. The model learns to favor the responses it prefers over rejected ones, all while using a reference model as a guide. This approach simplifies things by removing the need for rollouts, critics, and explicit reinforcement learning.
Rafailov, M., Dathathri, S., Dhariwal, P., & Nichol, A. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv. https://arxiv.org/abs/2305.18290
SDPO (Soft / Scaled DPO)
SDPO builds upon DPO by letting preferences be weighted or continuous instead of just yes or no. This makes it more effective at dealing with noisy or uncertain human judgments. It's especially well-suited for handling real-world preference data.
Yang, X., Tan, Z., Wang, J., Zhou, Z., & Li, H. (2025). SDPO: Importance-Sampled Direct Preference Optimization for Stable Diffusion Training. arXiv. https://arxiv.org/abs/2505.21893

IPO (Implicit Preference Optimization)
IPO explores learning preferences in a natural way, without needing explicitly labeled pairs. Instead, the model picks up on preference structures from its own internal signals or comparisons, making it less dependent on carefully curated datasets.
Gupta, A., Zhao, Y., Li, Z., Zhang, R., & Peng, X. (2025). Implicit Preference Optimization: Aligning Language Models Without Explicit Preference Pairs. arXiv. https://arxiv.org/abs/2502.16182
")
ORPO (Odds Ratio Preference Optimization)
ORPO seamlessly integrates instruction tuning with preference optimization, streamlining the process by eliminating the need for a separate RLHF stage. Its main focus is on maintaining simplicity and stability, making the approach more straightforward and reliable.
Hong, J., Lee, N., & Thorne, J. (2024). ORPO: Monolithic Preference Optimization without Reference Model. arXiv. https://arxiv.org/abs/2403.07691
Contrastive and margin-based methods
CPO (Contrastive Preference Optimization)
CPO clearly helps distinguish excellent responses from ordinary ones. Instead of just rewarding the best outputs, it also gently discourages less ideal options. This approach fine-tunes the model's behavior and makes it more reliable.
Xu, H., Sharaf, A., Chen, Y., Tan, W., Shen, L., Van Durme, B., Murray, K., & Kim, Y. J. (2024). Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation. arXiv. https://arxiv.org/pdf/2401.08417v4.pdf
Margin-based preference losses
Several methods utilize hinge or margin-style losses on preference pairs. These approaches are straightforward yet very effective, especially when the relative quality between options is more important than perfect calibration.
Human-aware objectives
 // align LLMs with human feedback by directly maximizing utility based on prospect theory | by evoailabs | Medium")
KTO (Kahneman–Tversky Optimization)
KTO models how humans respond differently to gains and losses. It tends to weigh losses more heavily than equal-sized gains, just like people do in real life. This approach helps the system make judgments that feel more natural and aligned with human perceptions of quality.
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., & Kiela, D. (2024). KTO: Model Alignment as Prospect Theoretic Optimization. arXiv. https://arxiv.org/abs/2402.01306
Risk-sensitive objectives
Some approaches focus more on preventing negative results rather than just maximizing overall rewards. This becomes especially important when safety and alignment are involved.
Markowitz, J., Gardner, R. W., Llorens, A. J., Arora, R., & Wang, I-J. (2022). A risk-sensitive approach to policy optimization. arXiv. https://arxiv.org/abs/2208.09106
Offline RLHF
Offline RLHF
Offline methods rely on pre-existing logged datasets, meaning they don't create new samples. This approach helps keep costs low and avoids exploration-related risks. However, it also means there's a limit to how much they can improve beyond what's in the dataset.
Cen, S., Mei, J., Goshvadi, K., Dai, H., Yang, T., Yang, S., Schuurmans, D., Chi, Y., & Dai, B. (2024). Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF. arXiv. https://arxiv.org/abs/2405.19320
Preference distillation
Some pipelines start by creating high-quality outputs, then use preference optimization. This approach helps enhance signal quality and makes the process more stable.
Kwon, M., Ko, J., Kim, K., & Kim, J. (2025). Preference Distillation via Value-based Reinforcement Learning. arXiv. https://arxiv.org/abs/2509.16965
The field is moving steadily from heavy reinforcement learning toward simpler, comparison-based preference optimization. Methods like GRPO and SDPO matter because they preserve alignment quality while dramatically reducing cost and complexity.
RLHF is no longer just “doing RL on language models.” It is becoming a family of techniques for learning human preferences efficiently and robustly.
This article comes at the perfect time, your explanation of RLHF is so clear and makess perfect sense. It makes me wonder about the fascinating challenge of scaling human alignment data and ensuring that 'preferences' account for diverse ethical frameworks, especially as these models become more intregrated into our lives.