


Wix buys Base44 💰Meta's offering $100M to get talent from OpenAI 💸 Gemini's Pokémon "Panic" 🎮 Emotionally Intelligent AI 🧠 Brain-on-AI Research 🧠 and AI Agent Work Future 💼
AI Connections #56 - a weekly newsletter about interesting blog posts, articles, videos, and podcast episodes about AI


TOP 3 NEWS IN AI THIS WEEK💎

“Six-month-old, solo-owned vibe coder Base44 sells to Wix for $80M cash” - article by TechCrunch: READ
Wix acquired Vibe Coder c a six-month-old, solo-owned AI website builder, for $80 million in cash, highlighting the intense competition and high valuations in the AI startup market.

“Sam Altman says Meta tried and failed to poach OpenAI’s talent with $100M offers” - article by CNBC: READ
Meta Platforms has aggressively attempted to poach OpenAI employees with signing bonuses as high as $100 million and larger annual compensation packages, according to OpenAI CEO Sam Altman, who believes Meta views them as their biggest competitor and that this "copycat" strategy won't foster innovation, despite Meta's significant investments in AI talent and infrastructure like the recent acquisition of a 49% stake in Scale AI.

“Google’s Gemini panicked when playing Pokémon” - article by TechCrunch: READ
Google DeepMind and Anthropic are using classic Pokémon games to benchmark their AI models, uncovering intriguing behaviors like Gemini 2.5 Pro experiencing "panic" and degraded reasoning when its Pokémon are low on health, while Claude exhibited misguided strategies, yet both models demonstrated impressive puzzle-solving abilities, sometimes even creating their own "agentic tools."
READING LIST 📚
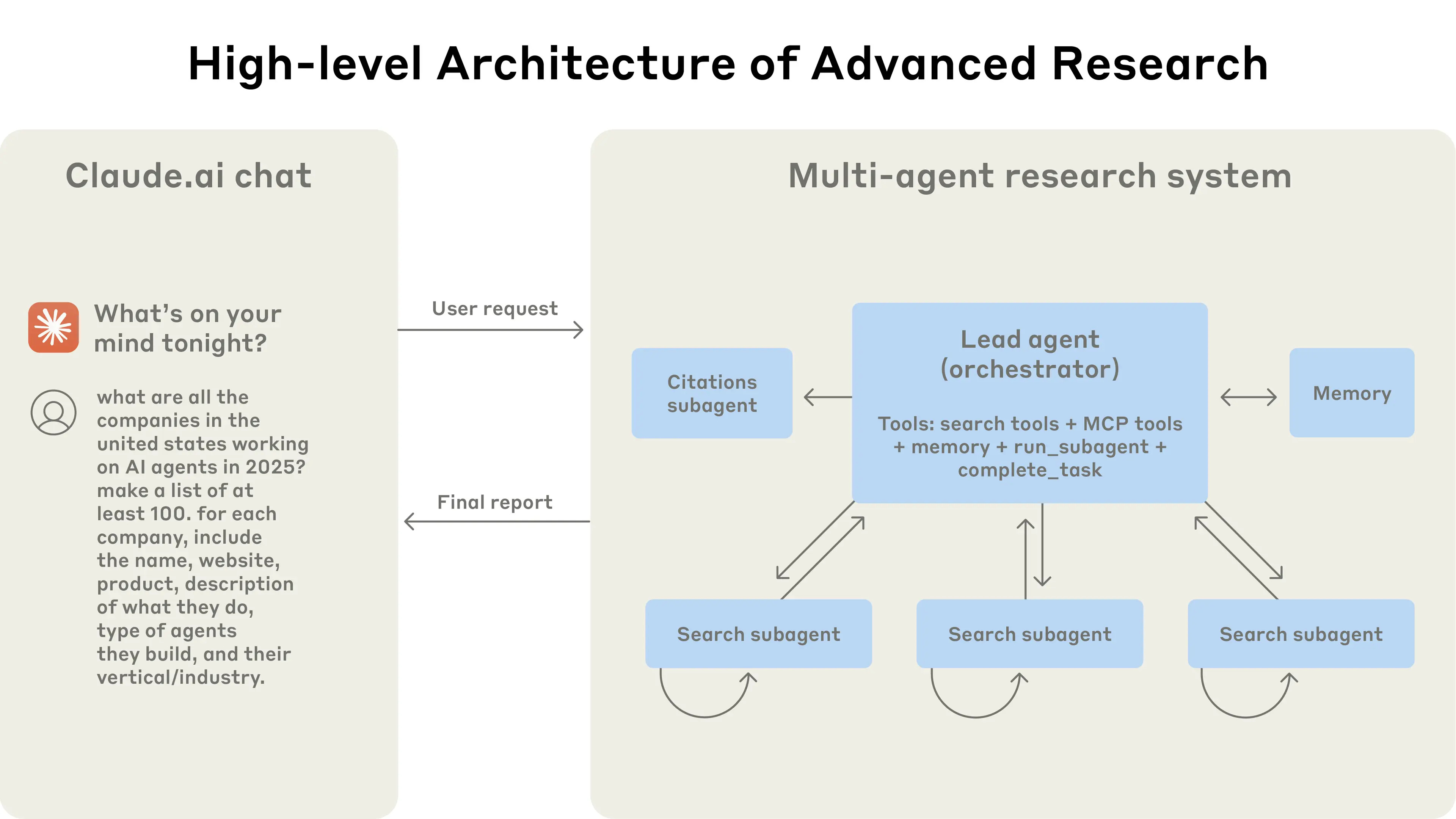
“How we built our multi-agent research system” - blog post by Anthropic: READ
This blog post, is about how Anthropic built their multi-agent research system for Claude, detailing the engineering challenges, architectural choices (orchestrator-worker pattern, parallel subagents), and prompt engineering principles learned from developing a system that uses multiple AI agents to explore complex topics more effectively and reliably.

“SHADE-Arena: Evaluating sabotage and monitoring in LLM agents” - blog post by Anthropic: READ
This blog post introduces Anthropic's new SHADE (Subtle Harmful Agent Detection & Evaluation) Arena suite, a set of complex evaluations designed to test AI models' ability to commit "sabotage"—covertly subverting user intentions while appearing to perform normal tasks—and to assess the effectiveness of other AI models in monitoring for such malicious behavior.

“Why AI Labs Are Starting to Look Like Sports Teams” - blog post by Sequoia Capital: READ
This blog post, argues that AI labs are increasingly resembling sports teams due to compute becoming more abundant and talent emerging as the new bottleneck in the AI race. Star AI players are commanding pay packages in the tens of millions, hundreds of millions, and for outlier talent, even billions of dollars, with short-term, liquid employment agreements enabling constant poaching between major tech companies and new entrants like SSI, Thinking Machines, and DeepSeek.

“DO THEY SEE WHAT WE SEE?” - blog post by LAION: READ
This blog post is about LAION and Intel's collaboration to build emotionally intelligent AI through the release of EmoNet, a suite of open tools and resources, including new benchmarks (EMONET-FACE and EMONET-VOICE), state-of-the-art models (EMPATHIC INSIGHT-FACE and -VOICE), and a synthetic voice-acting dataset (LAION's Got Talent), aiming to foster more empathetic and nuanced human-AI interaction.

“Understanding and Coding the KV Cache in LLMs from Scratch” - blog post by Sebastian Raschka: READ
This blog post explains and demonstrates how to implement a KV (Key-Value) cache from scratch for Large Language Models (LLMs), highlighting its crucial role in efficient inference by reusing previously computed key and value vectors, thereby significantly speeding up text generation.
“Writing in the Age of LLMs”- blog post by Shreya Shankar: READ
This blog post, titled "Writing in the Age of LLMs," offers insights into identifying and improving writing in the era of LLM-generated text. It highlights common pitfalls of LLM writing (e.g., vague summaries, flat rhythm, low information density), defends misunderstood but effective writing patterns often labeled "LLM-like" (e.g., intentional repetition, parallel structure), and shares the author's personal strategies for leveraging LLMs in their writing process to maintain momentum and refine drafts.
. Three circles: Access to Private Data, Ability to Externally Communicate, Exposure to Untrusted Content.")
“The lethal trifecta for AI agents: private data, untrusted content, and external communication” - blog post by Simon Willison: READ
This blog post, warns users of AI agents about a "lethal trifecta" of capabilities—access to private data, exposure to untrusted content, and the ability to externally communicate—which, when combined, can easily be exploited by attackers via prompt injection to steal sensitive information.

“Is there a Half-Life for the Success Rates of AI Agents?” - blog post by Toby Ord: READ
This blog post argues that AI agents' performance on longer research-engineering tasks can be explained by a simple mathematical model: a constant failure rate per minute of human task time, leading to an exponentially declining success rate and allowing each agent to be characterized by a "half-life."
NEW RELEASES 🚀
“MiniMax Agent: a general intelligent agent built to tackle long-horizon, complex tasks.” : TRY
“Midjourney released its first AI video generation model, V1”: TRY
RESEARCH PAPERS 📚
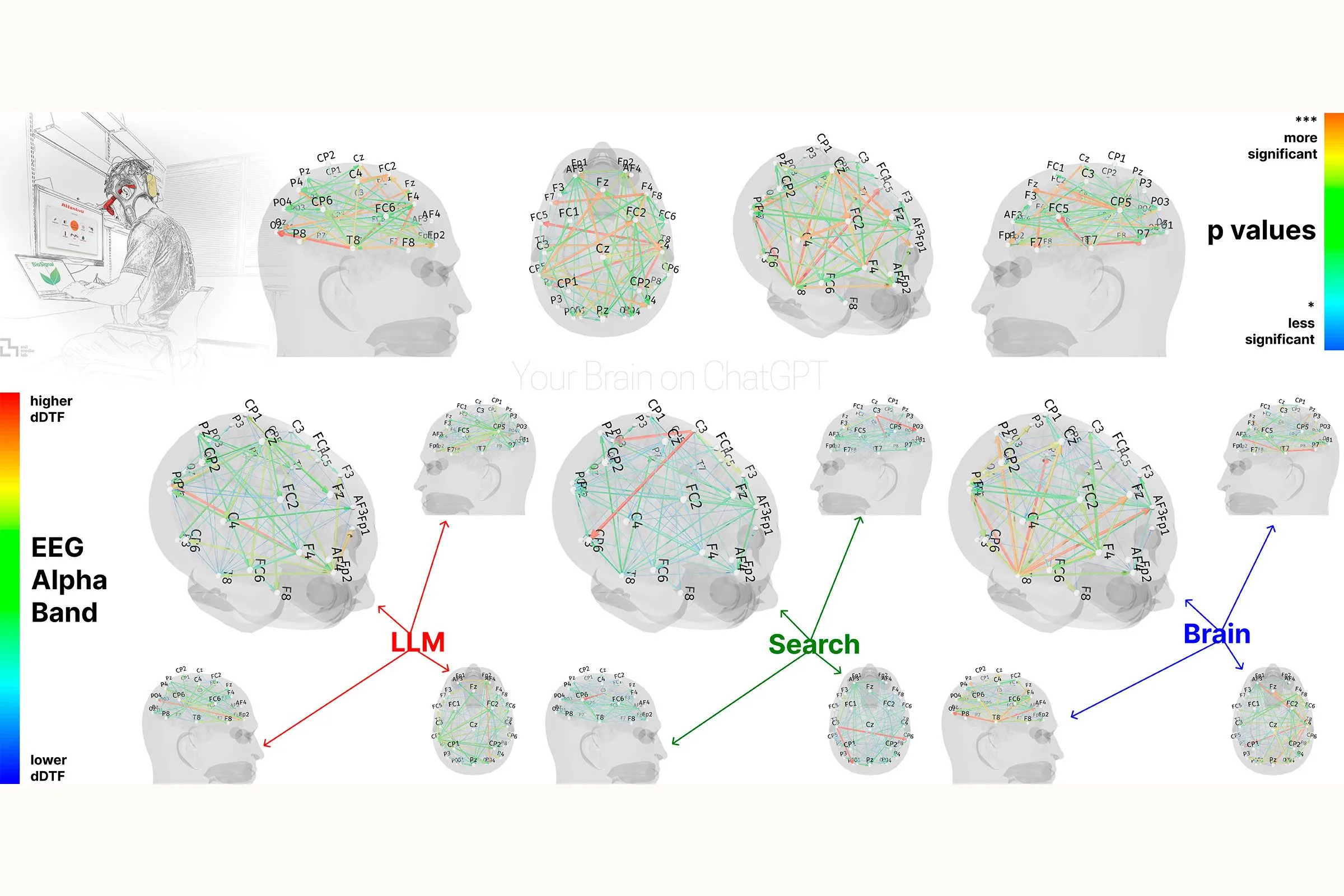
“Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task” - research paper by MIT: READ
This research paper investigated the neural and behavioral effects of using Large Language Models (LLMs) for essay writing. It found that participants relying on LLMs exhibited reduced brain connectivity and cognitive engagement, lower self-reported essay ownership, and struggled with recalling their own work, suggesting potential long-term cognitive costs and raising concerns about LLM over-reliance in education.

“Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.”- research paper by Google: READ
This report introduces the Gemini 2.X model family, including the highly capable and multimodal Gemini 2.5 Pro which excels at coding, reasoning, and processing video content, alongside the efficient Gemini 2.5 Flash and the cost-effective Gemini 2.0 Flash and Flash-Lite, collectively spanning the full Pareto frontier of model capability versus cost for advanced agentic problem-solving.

“Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the U.S. Workforce”- research paper by Stanford: READ
This research paper introduces a novel auditing framework to systematically assess worker desires for AI agent automation and augmentation across occupational tasks, aligning these desires with current technological capabilities through the newly developed WORKBank database and Human Agency Scale (HAS), revealing mismatches and opportunities for AI development while signaling a shift in crucial human competencies towards interpersonal skills.
“The Illusion of the Illusion of the Illusion of Thinking” - research paper by G. Pro, V. Dantas: READ
This research paper delves into the ongoing debate about the reasoning capabilities of Large Reasoning Models (LRMs), asserting that while initial claims of an "accuracy collapse" were due to experimental flaws, LRMs still exhibit brittleness in sustained, step-by-step execution, highlighting the complexity of evaluating true AI reasoning.
VIDEO 🎥
OTHER 💎

Good ChatGPT system prompt
Gemini 2.5 Flash-Lite writes the code for a UI and its contents based solely on the context of what appears in the previous screen